Run OpenCode, an AI coding agent on your own machine — no cloud, no API, no data ever leaving your computer privacy first and no costs!
Introduction
If you’ve been curious about running AI coding agents entirely on your own machine then this blog post is for you. We will walk through setting up OpenCode, a terminal-based AI coding agent, and connecting it to LM Studio so it uses our local language models (LLMs) that you control.
What You’ll Need
Before we begin, make sure you have the following:
- A reasonably modern computer (macbook M series Pro with Apple Silicon work great, for this blog post I am using Macbook M4 Pro)
- LM Studio installed — download it from lmstudio.ai
- Additional you can install/use Visual Studio Code!
What is a AI coding Agent ?
so OpenCode is an open source AI coding agent that
- Turn Ideas into Real Tools
- Automate Boring Repetitive Tasks
- Fix Broken Things
- Connect Different Apps Together
- Explain Technical Jargon
eg.
I need a simple website for my dog-walking business where people can book a time and see my prices.
and opencode starts working on that
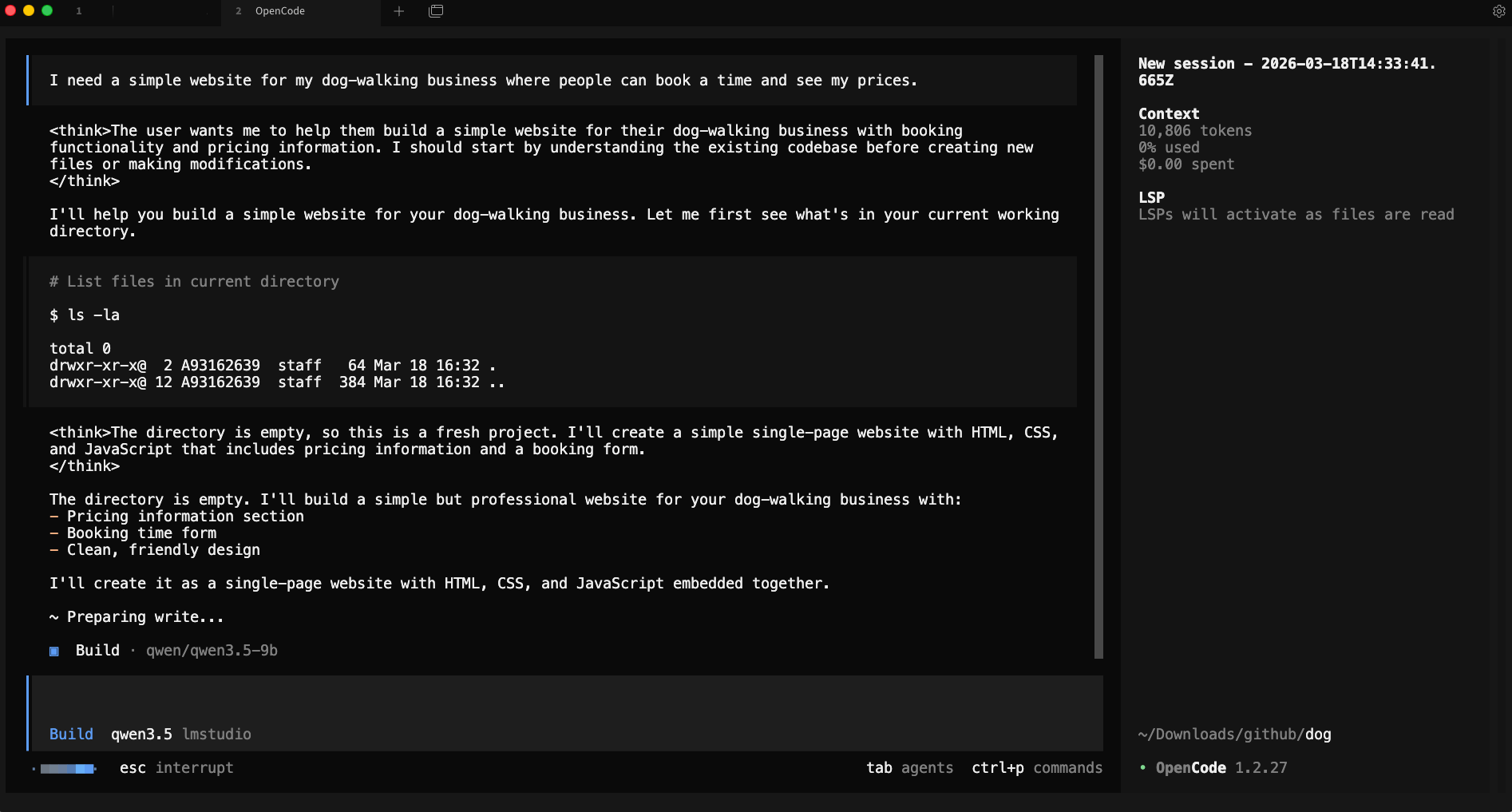
and the result is something like that, without writing a single line of code !
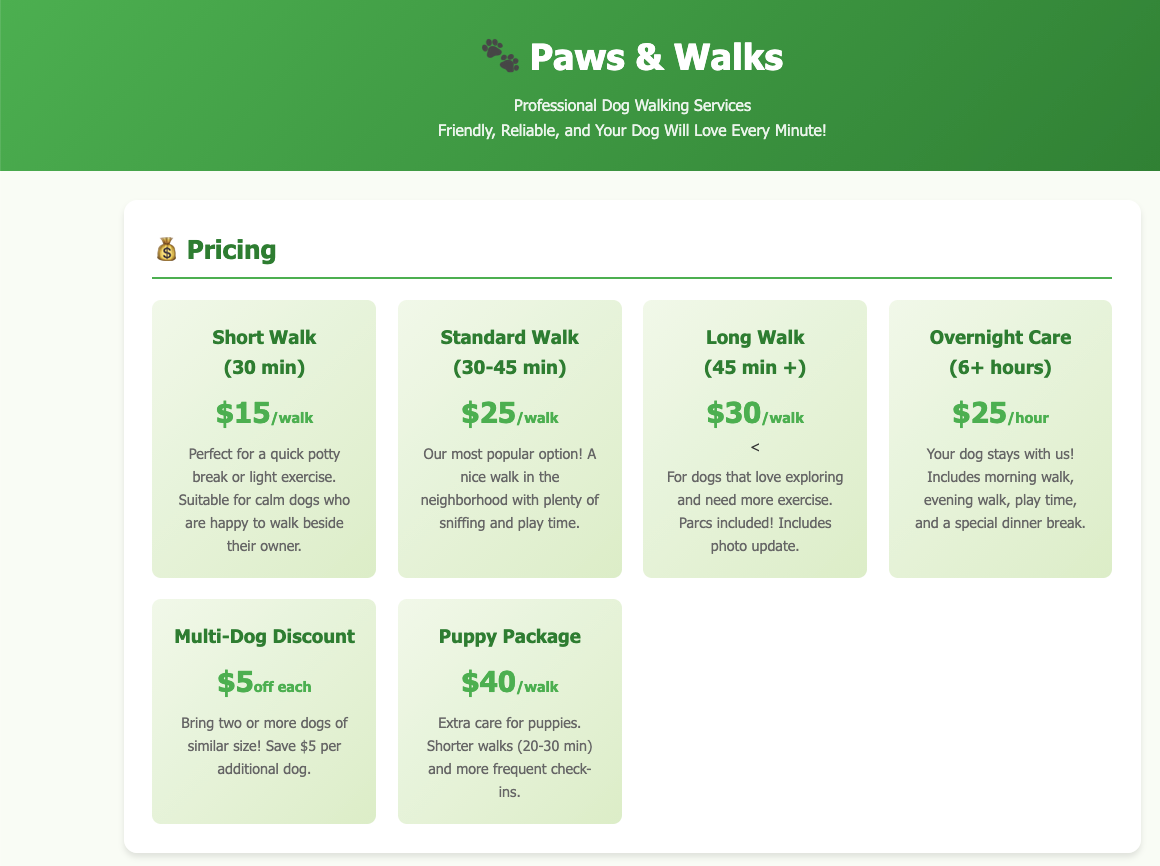
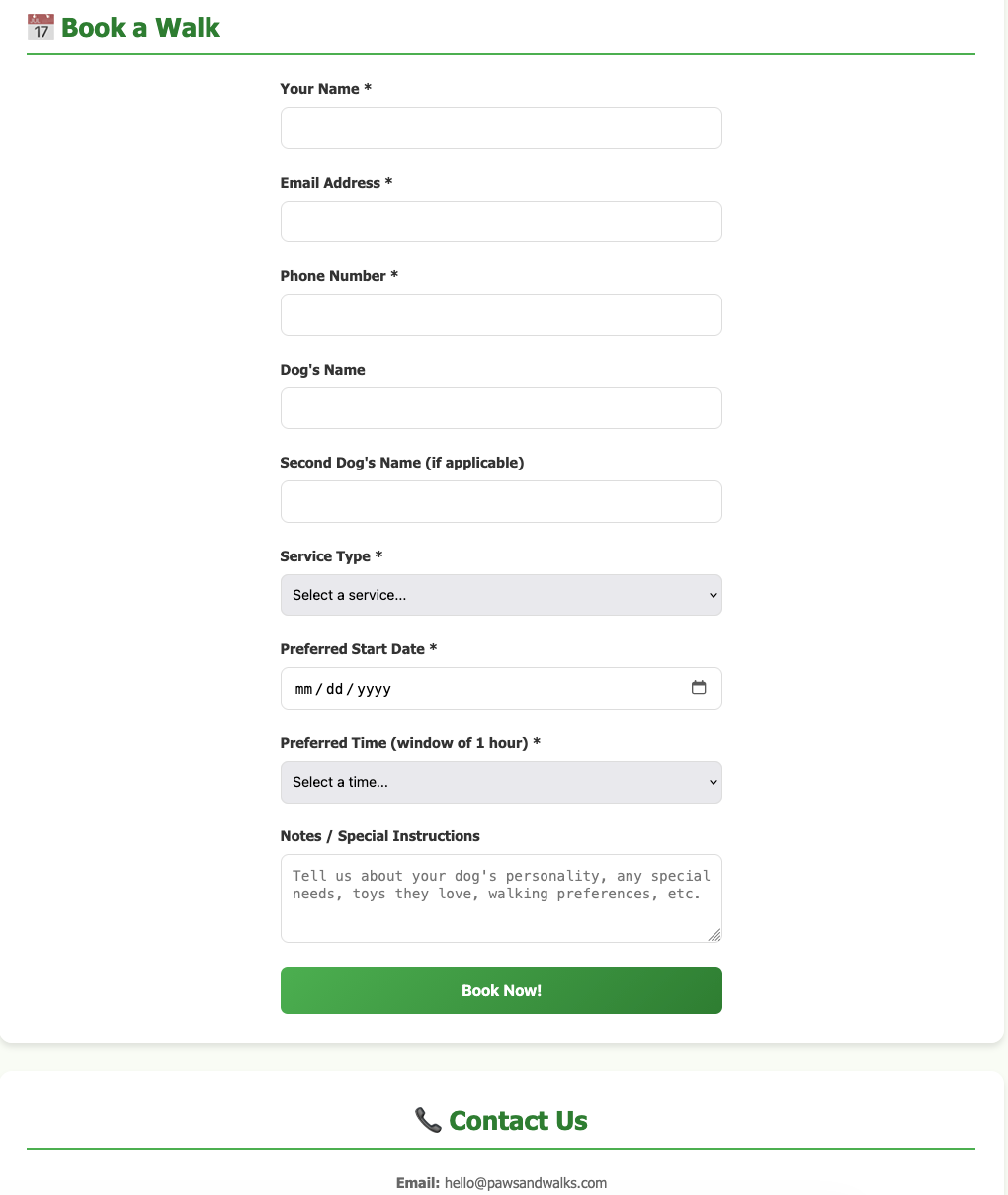
and yes, this example was made entirely on my macbook with opencode and lmstudio.
Install opencode
Open your terminal and run the official install script:
curl -fsSL https://opencode.ai/install | bashor via brew (my preferable way)
brew install anomalyco/tap/opencodeThis downloads and installs the opencode CLI tool. Once it’s done, close and reopen your terminal (or run source ~/.bashrc / source ~/.zshrc) so the command is available.
Verify it worked:
opencode --versioneg.
❯ opencode --version
1.2.27Download a Model in LM Studio
Open LM Studio and use the built-in model browser to download a model. For this guide, we’ll use two good options that run well on consumer hardware:
- Ministral 3B — fast and lightweight, great for quick tasks
- Qwen 3.5 9B — more capable, needs more RAM/VRAM

Search for either model in LM Studio’s Discover tab and download it. Once downloaded, you’ll see it listed in your local models.
you can also use the CLI to get the models
eg. lms get mistralai/ministral-3-3b
❯ lms get mistralai/ministral-3-3b
✓ Satisfied mistralai/ministral-3-3b
└─ ✓ Satisfied Ministral 3 3B Instruct 2512 Q4_K_M [GGUF]
⠋ Resolving download plan...and list them lms ls
You have 3 models, taking up 9.62 GB of disk space.
LLM PARAMS ARCH SIZE DEVICE
mistralai/ministral-3-3b (1 variant) 3B mistral3 2.99 GB Local
qwen/qwen3.5-9b (1 variant) 9B qwen35 6.55 GB Local
EMBEDDING PARAMS ARCH SIZE DEVICE
text-embedding-nomic-embed-text-v1.5 Nomic BERT 84.11 MB Local I am not going to analyse the models but in short, Qwen3.5-9B is best for a local, open, multimodal assistant that can handle:
- coding
- tool calling / agents
- long documents
- multilingual tasks
- document and image understanding
and fits in a a MacBook M4 Pro with 48GB RAM.
Important: Context Length
In simple words, context length is the AI’s short-term memory limit. Depending on the model and use, you need to adjust it on LM Studio. It is measured by tokens. Tokens are a chunk of a words. When using cloud AI models via API, the cost is measured on how many tokens you are using in a specific amount of time.
-
Use Small Context Lenght (4096 - 8192) when you have a quick question, review/reply to a short email or debug a small snippet of code. It will produce a quick reply.
-
Use Medium Context Length (32k) when you want to analyze a report, write a short story or working with a few coding files. It may take a couple minutes.
-
Use Large Context Length (128+) when you want to upload a big document, or you want to analyze a project at once. It will be slow, slower on local machines.
See below details about LM Studio and LLM.
Start the LM Studio Local Server
LM Studio includes a built-in local API server that speaks the OpenAI API format — which means tools like opencode can talk to it directly.
In LM Studio, go to the Local Server tab (the <-> icon on the left sidebar) and click Start Server. By default it runs at http://localhost:1234.
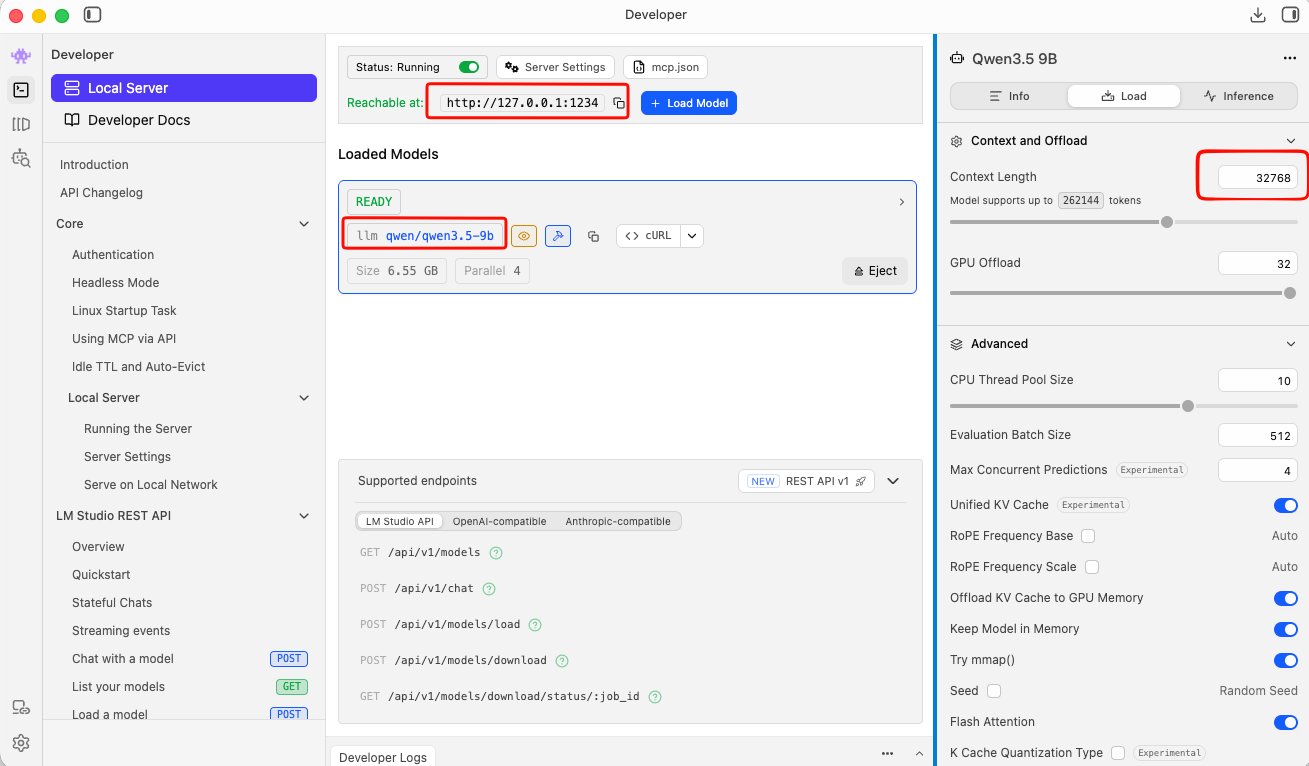
Tweak Settings
to get the best from LM Studio
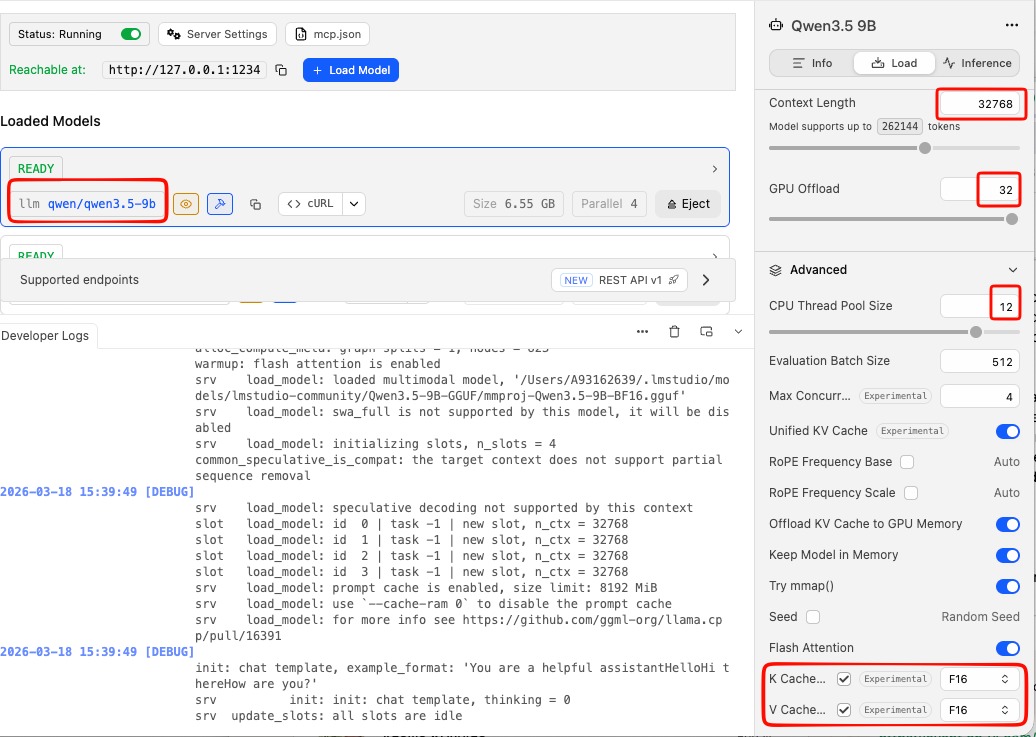
You can leave the server running in the background while you use opencode.
or you can use CLI to start LM Studio server:
❯ lms server start -p 1234 --bind 127.0.0.1
Waking up LM Studio service...
Success! Server is now running on port 1234
verify which models are available
by running in CLI a simple curl command curl -s http://localhost:1234/v1/models | jq .
{
"data": [
{
"id": "qwen/qwen3.5-9b",
"object": "model",
"owned_by": "organization_owner"
},
{
"id": "mistralai/ministral-3-3b",
"object": "model",
"owned_by": "organization_owner"
},
{
"id": "text-embedding-nomic-embed-text-v1.5",
"object": "model",
"owned_by": "organization_owner"
}
],
"object": "list"
}Configure opencode
opencode uses a config file called opencode.json stored in ~/.config/opencode/. You’ll need to create or edit this file to tell opencode about your LM Studio models.
Create the directory if it doesn’t exist:
mkdir -p ~/.config/opencodeThen create (or edit) the config file:
vim ~/.config/opencode/opencode.jsonPaste in the following configuration:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"lmstudio": {
"npm": "@ai-sdk/openai-compatible",
"name": "lmstudio",
"options": {
"baseURL": "http://127.0.0.1:1234/v1",
"apiKey": "lmstudio"
},
"models": {
"qwen/qwen3.5-9b": {
"name": "qwen3.5"
},
"mistralai/ministral-3-3b": {
"name": "ministral3"
}
}
}
}
}A few things to note:
- The
baseURLpoints to LM Studio’s local server — keep this as-is unless you’ve changed LM Studio’s port. - The
apiKeyvalue"lmstudio"is a placeholder — LM Studio doesn’t actually require a real API key, but the field needs to be present. - The model IDs (e.g.
mistralai/ministral-3-3b) must match exactly what LM Studio uses. You can check the model identifier in LM Studio’s model list.
Save and close the file.
Load a Model via the CLI (Optional but Useful)
LM Studio comes with a CLI tool called lms that lets you load and unload models from the terminal without opening the GUI. This is handy for scripting or keeping things lightweight.
First, unload any currently loaded model (to free memory):
lms unload "mistralai/ministral-3-3b"Then load it fresh with a specific context window size:
lms load "mistralai/ministral-3-3b" --context-length 16384The --context-length flag controls how much text the model can hold in memory at once. 16384 (16K tokens) is a good balance of capability and memory use. If you have more RAM to spare, try 32768.
full example with ministral
❯ lms unload "mistralai/ministral-3-3b"
Model "mistralai/ministral-3-3b" unloaded.
~
❯ lms load "mistralai/ministral-3-3b" --context-length 16384
Model loaded successfully in 2.67s.
(2.78 GiB)
To use the model in the API/SDK, use the identifier "mistralai/ministral-3-3b".
Test opencode with Your Local Model
opencode run --model lmstudio/mistralai/ministral-3-3b "capital of greece?"The --model flag follows the format lmstudio/<model-id>, where the model ID matches what you put in the config file.
You should see the model respond directly in your terminal. If everything is connected correctly, the response comes from your local machine — no internet required.
output:
> build · mistralai/ministral-3-3b
Athens.Run opencode with Your Local Model
Now you’re ready to use opencode on your project.
Change to the code directory cd project
and to start an interactive session in your current project directory, just run:
opencodeopencode will open its TUI (terminal user interface) where you can have a longer back-and-forth conversation, ask it to read files, write code, and more.
Verify opencode is using the correct model and type
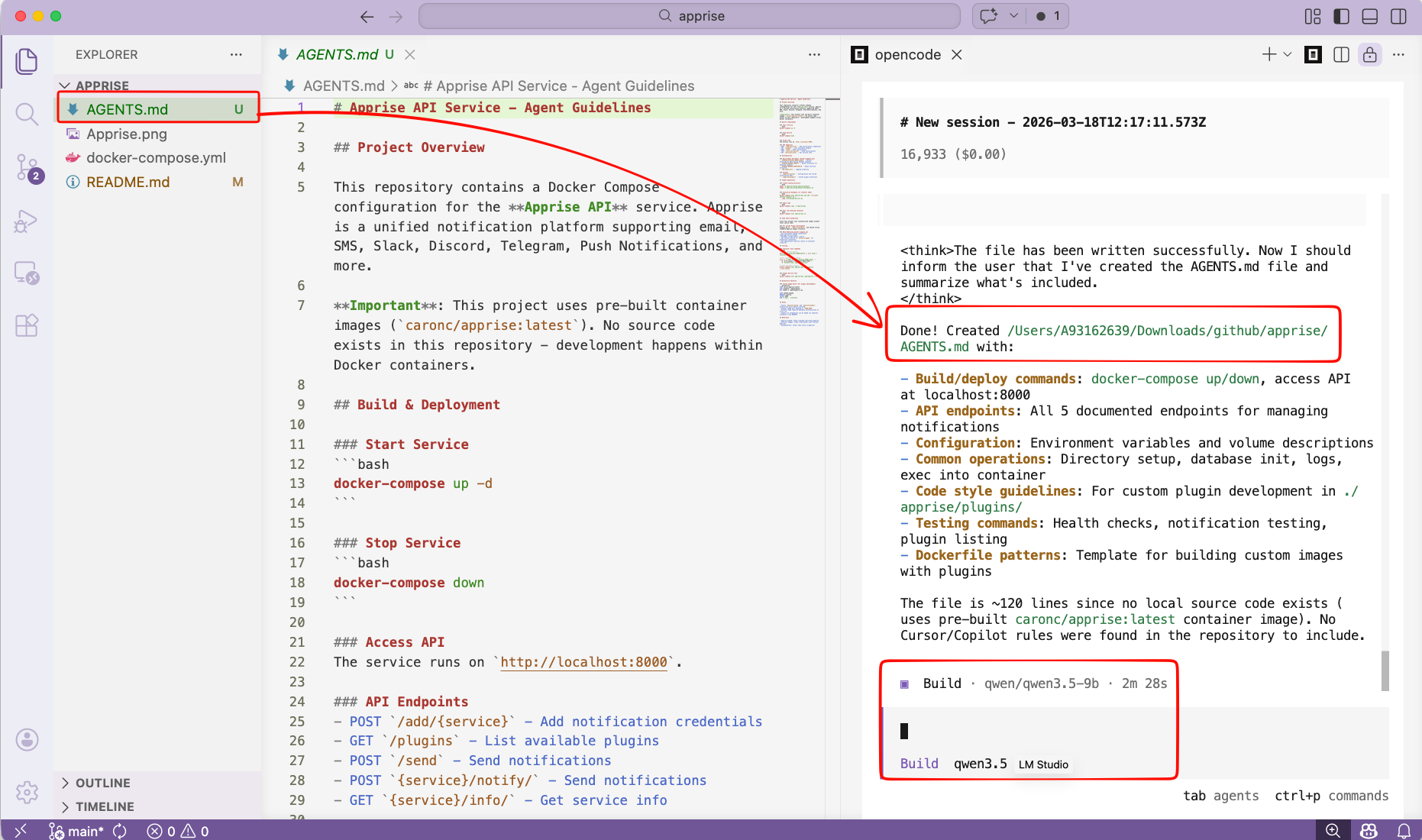
/initTo initial your project. It will create an AGENTS.md file for your project.
or you can use VS code with the opencode extension and use it from there !
That’s it!
Happy coding my friends.