LiteLLM AI Gateway (LLM Proxy)
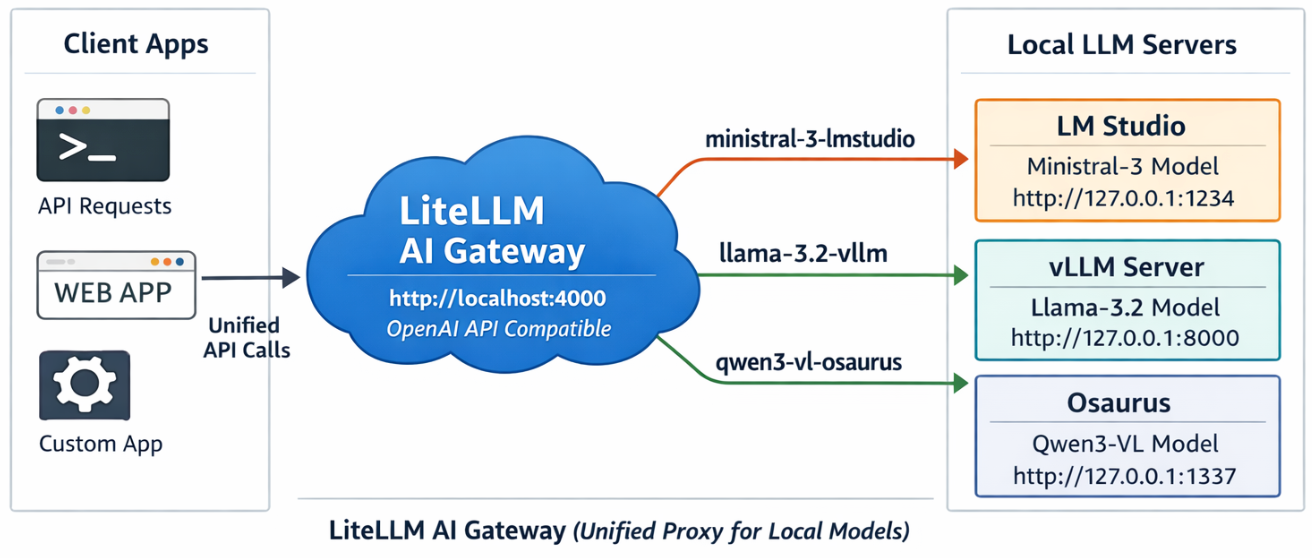
This project shows a simple pattern: run multiple local model servers, place LiteLLM in front of them, and expose one OpenAI-compatible endpoint for apps to use.
In this setup, Lite LLM sits on http://127.0.0.1:4000/v1 and routes requests to:
- LM Studio on port
1234 - vLLM on port
8000 - Osaurus on port
1337
That gives you one clean API for local testing, model switching, and app integration.
Why this setup is useful
If you already have local models running in different tools, LiteLLM gives you one gateway instead of several different endpoints.
That means you can:
- keep one API base URL
- switch models by alias
- expose multiple local backends behind the same interface
- plug the endpoint into apps that expect an OpenAI-style API
What this article shows
This guide walks through the full flow:
- LiteLLM exposes
/v1/modelsand returns the three configured aliases. - A chat app can select one of those LiteLLM model names and answer normally.
- Khoj can be pointed at LiteLLM by setting the API base to
http://127.0.0.1:4000/v1. - Khoj chat models can then use a LiteLLM alias such as
ministral-lmstudio.
Quick start
Use Python 3.12 or 3.13 for the LiteLLM virtual environment to avoid uvloop path a known incompatibility with Python 3.14’s asyncio internals.
Set up a virtual environment
virtualenv -p python3.12 venv-litellm/
cd venv-litellm/
source ./bin/activate
pip install "litellm[proxy]"LiteLLM Configuration
Create config.yaml:
Below is an example based on my local setup.
model_list:
- model_name: ministral-lmstudio
litellm_params:
model: openai/mistralai/ministral-3-3b
api_base: http://127.0.0.1:1234/v1
api_key: lmstudio
- model_name: llama3-vllm
litellm_params:
model: openai/mlx-community/Llama-3.2-3B-Instruct-4bit
api_base: http://127.0.0.1:8000/v1
api_key: vllm
- model_name: qwen3-osaurus
litellm_params:
model: openai/qwen3.5-0.8b-mlx-4bit
api_base: http://127.0.0.1:1337/v1
api_key: osaurusYou need the openai/ prefix for each model to use LiteLLM’s OpenAI-compatible provider.
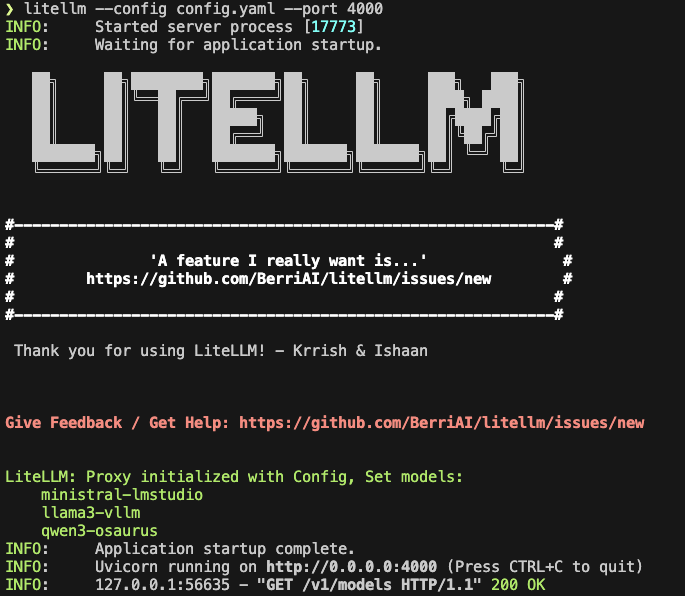
Start LiteLLM
litellm --config config.yaml --port 4000If LiteLLM starts correctly, you should see the three model aliases loaded.
Test the proxy
List models:
curl -s http://127.0.0.1:4000/v1/models | jq .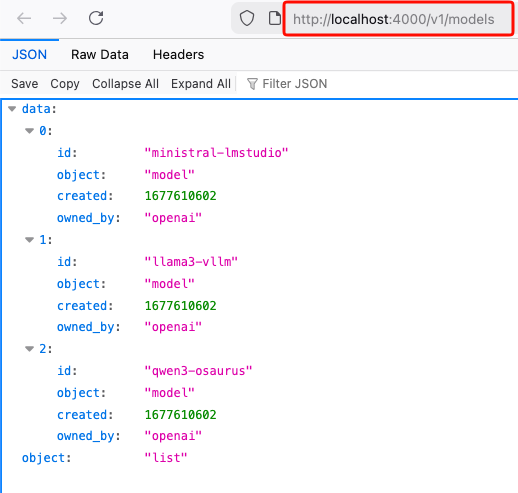
Test chat
Send a chat request:
curl -s http://127.0.0.1:4000/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "ministral-lmstudio",
"messages": [
{"role": "user", "content": "Capital of Greece?"}
]
}' | jq .If everything is wired correctly, LiteLLM will forward the request to the matching backend and return a normal OpenAI-style response.
A typical result looks like this:
{
"id": "chatcmpl-oukopuooxti6xg92g6qx9b",
"created": 1773142359,
"model": "ministral-lmstudio",
"object": "chat.completion",
"system_fingerprint": "mistralai/ministral-3-3b",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "The capital of Greece is **Athens**.",
"role": "assistant",
"provider_specific_fields": {
"refusal": null
}
},
"provider_specific_fields": {}
}
],
"usage": {
"completion_tokens": 10,
"prompt_tokens": 539,
"total_tokens": 549
},
"stats": {}
}Connect LiteLLM to Khoj
You can use the same LiteLLM endpoint with any app that supports an OpenAI-style API. In this example, I use Khoj.
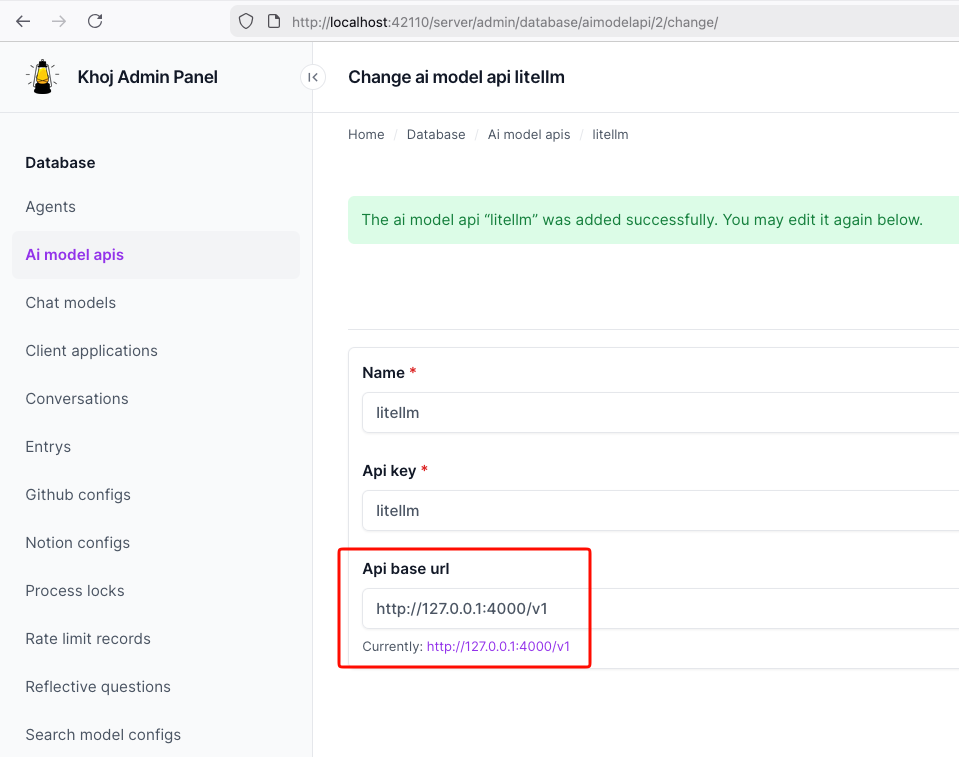
Once LiteLLM is running, Khoj only needs one API configuration:
- Name:
litellm - API key:
litellm - API base URL:
http://127.0.0.1:4000/v1
Then create a chat model in Khoj using one of the LiteLLM aliases, for example:
ministral-lmstudio
That is the key idea of this project: Khoj does not need to know whether the model is coming from LM Studio, vLLM, or Osaurus. It only talks to LiteLLM.
Khoj AI model API configuration
Khoj chat model configuration
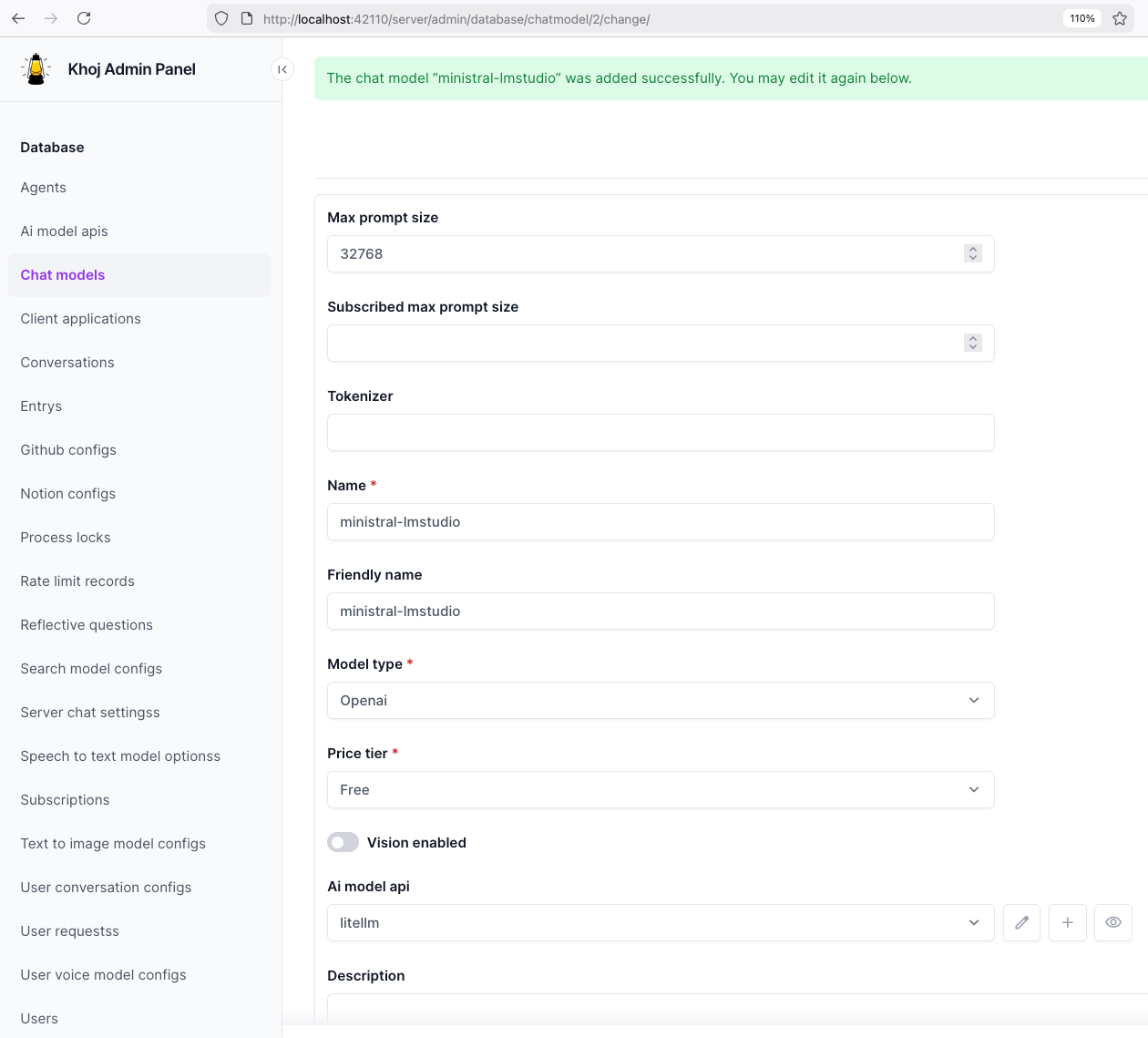
Khoj using a LiteLLM chat model
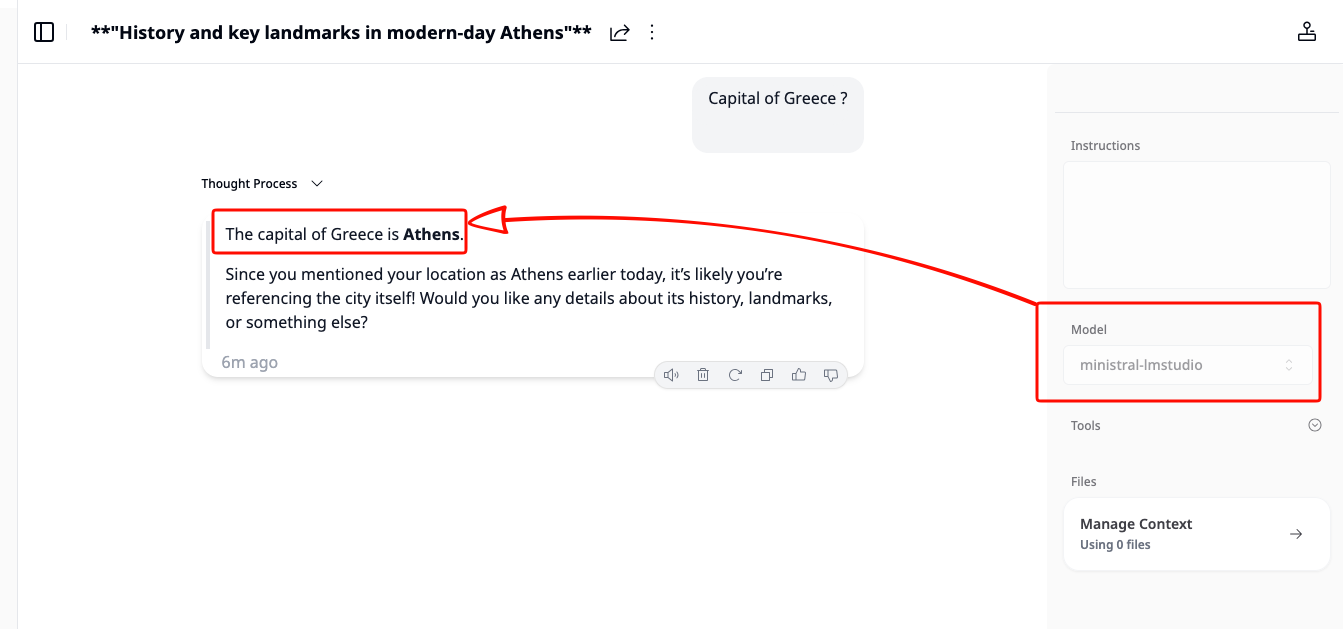
That’s it!